Journal Club: Validation of LSV and RP-HPLC to determine content and purity

Introduction and background
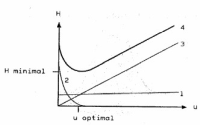
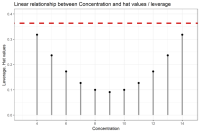
Fulvestrant or Faslodex is a drug used to cure hormone receptor-positive (HR+) metastatic breast cancer in postmenopausal women with disease progression. It belongs to the group of Selective Estrogen Receptor Downregulators (SERD) and is often considered a suitable replacement for Tamoxifen. It functions by binding to the estrogen receptor and destabilizing it, promoting degradation by the cell's normal protein degradation mechanism. For Fulvestrant’s content determination in pure and pharmaceutical dosage form or its purity, there has been no HPLC (High Performance Liquid Chromatography) or LSV (Linear Sweep Voltammetry) methods reported thus far. In this post, we would like to highlight such methods, developed by Atila et al., with focus on their advantages and compliance to method validation.