Method optimization to increase sensitivity in case of LOQ / LOD problems
In our first blog article on increasing the sensitivity in case of limit of detection (LOD) / limit of quantitation (LOQ) problems in HPLC methods, we addressed the increase in sensitivity primarily by reducing baseline noise. Now we will look on the same topic from another perspective – with the eyes of “method optimization”. What can be optimized to increase the peak size and thus the overall signal to noise ratio (S/R)?
In this blog post, we will not discuss the unusual issues such as leaks, contaminations, pressure fluctuations or changes in peak shape due to column aging. We assume the established method being robust and therefore don’t care about the usual troubleshooting themes.
"Peak sharpening" by gradient runs
The height of a peak depends on multiple factors. There is a direct relation between the height and the width of a peak: A flat, wide peak may have the same area as a narrow, high peak. However, while the broad peak can fail regarding requirements for signal to noise ratio, chances for the sharp and higher peak are much better. First of all, the basics of the method should be reflected. Is it performed using an isocratic mobile phase (fixed concentration, e.g. 50% acetonitrile) or using a gradient (varied concentration, like 0% - 100% acetonitrile)? An isocratic program has the advantage that the column doesn’t need not be washed after the end of the run, saving time and solvents. The disadvantage is that the peaks are often wider than in gradient runs. If the signal to noise ratio is not strong enough, it is worth switching to a gradient. A solvent gradient leads to "sharpening" of the peaks, i.e. to narrowing and thus also to increase.
It should be noted, however, that not every gradient is used ideally. For example, if the retention time of peak peak is very high, extending the gradient reduce both the retention time and the peak width. This is useful when separating a mixture of analytes as the resolution between different peaks improves. Let’s check this, considering a reversed phase (RP) HPLC. Imagine a run where a linear gradient from 100% water (polar) to 100% acetonitrile is used within 45 minutes. The analyte elutes only at about 80% acetonitrile from the column (see Figure 1: original method). If the sample composition is not too complex, it is worthwhile decreasing the “steepness” i.e. changing the gradient from initial 0% - 100% acetonitrile to 60% -100% acetonitrile in, for example, 15 minutes (Figure 1: limited gradient). This way a shorter analysis time, sharper peaks and a shorter washing time can be attained. For more complex samples containing several analytes of different polarity, the separation can be achieved by “steeping” the gradient further (from 0% to 100% acetonitrile but shortening the analysis time to 20 minutes instead of 45 minutes) (Figure 1: steeper gradient). It is important that all analytes remain well separated.

In simple analyzes with very few sample components, one can go one step further and use a shorter column to achieve shorter retention times.
The column parameters as influencing factor
If a long, flat gradient is necessary to separate all analytes, a look at the column parameters will help: The assumption that the longer a column, the better the resolution, is in principle not wrong - however, the particle size and the inner diameter of the column often have much stronger influence than anticipated on the resolution, peak width, and peak height. Comparing two columns of equal length, reducing the column diameter from 4.6 mm to 3 mm can increase the peak height to up to 5 times while improving resolution. But pay attention: if the same flow rate (mL/min) is applied for both mentioned inner diameters, the flow velocity (also linear velocity, e.g. cm/min) increases with decreasing inner diameter. A flow rate being too high is resulting in higher back pressure and degraded resolution and sensitivity. For each column, there is an efficiency maximum in respect to the flow rate, that is usually stated in the manufacturer's information to avoid loss of separation. If the flow rate is adjusted in a way that the flow velocities of both the columns are the same, the retention times remain similar, while sensitivity and solvent consumption are reduced.
With "cleaner" samples (or being purified before) it is worthwhile to switch to a smaller particle size to further increase the resolution. It should be noted that at constant column length, the back pressure increases significantly with decreasing particle size. The reduction in particle size can often work very well together with a shorter column, thereby reducing the back pressure. With this "minimization" of the system, the method can be optimized efficiently: The shortened column has a lower resolution compared to a longer column. This is compensated using smaller particles and a smaller inner diameter, which provides better sensitivity and resolution (see figure):
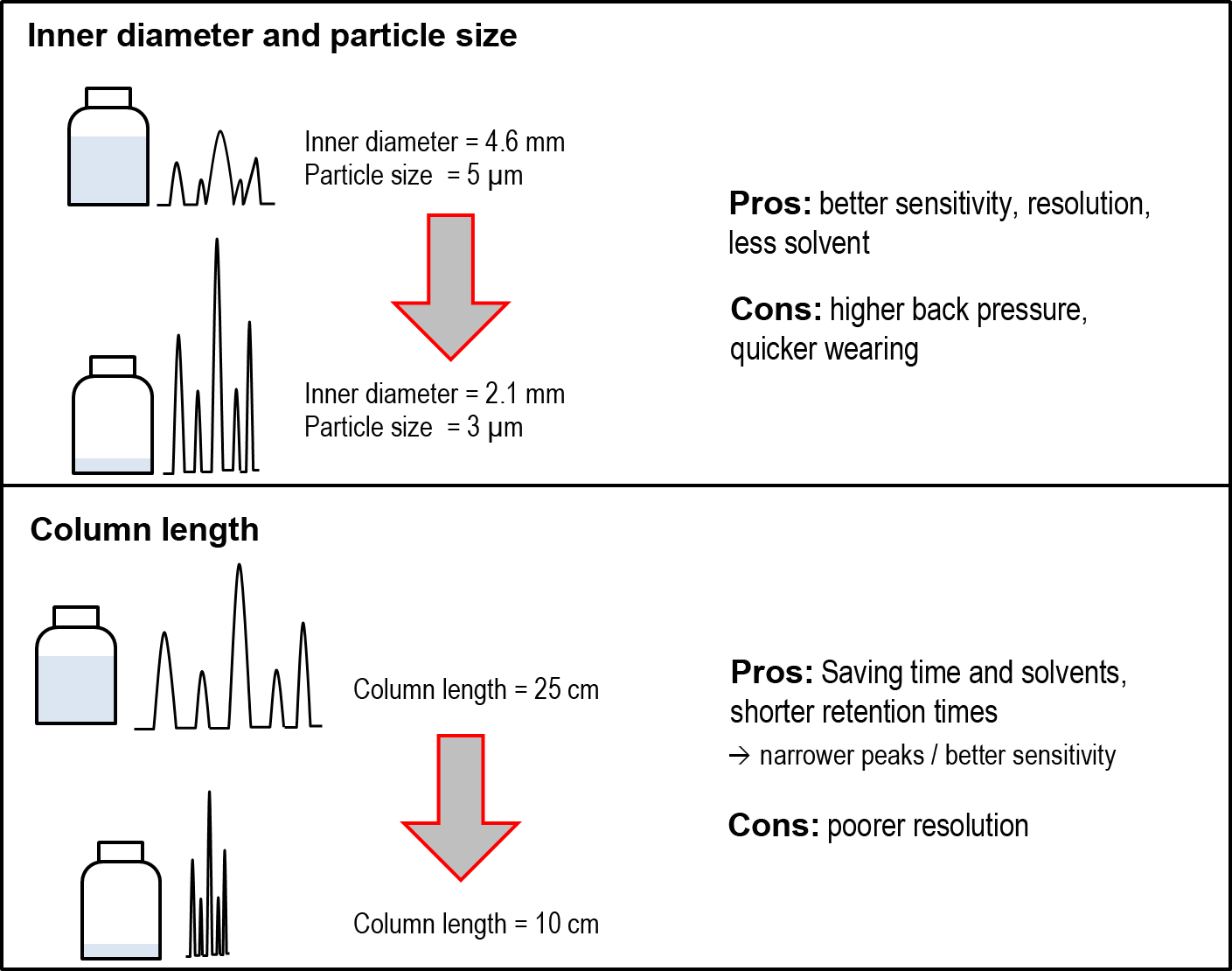
By keeping the flow velocity constant (due to appropriate reduction of flow rate), converting a 25 cm column with 5 μm particles and an inner diameter of 4.6 mm to a 12.5 cm column with 3 μm particles and inner diameter of 2.1 mm will increase the peak height many times (by reducing particle size and inner diameter), while the retention time will be halved (by lowering the column length to half). Depending on the complexity of the sample, the resolution can be improved with a change in column length.
Additionally, we should have a look on core-shell columns: While conventional silica particles are irregular and fully porous, core-shell particles have an impermeable core ("core") of uniform size. This core is surrounded by a porous shell (hence "shell"), with which the interactions take place. Due to the uniform size of the particles, a more orderly packing of the column is possible, which leads to lower pressures. The swirling and diffusion of the analytes is significantly reduced by the reduced depth of the shell compared to fully porous particles, resulting in analytes eluting in narrower peaks with often shorter retention times.
The disadvantage of core-shell columns and very small-sized columns, is the lower loading capacity and higher sensitivity to strong sample solvents (see also our blog articles about peak broadening and fronting / tailing). As a result, dilution of the sample and / or replacement of the sample solvent is often deemed necessary.